Concept Distribution Modeling
ETC captures contextual variation by fitting Student's t-distribution mixtures to low-rank text embedding distributions.
Large-scale text-to-image diffusion models deliver remarkable visual fidelity but pose safety risks due to their capacity to reproduce undesirable content, such as copyrighted ones. Concept erasure has emerged as a mitigation strategy, yet existing approaches struggle to balance scalability, precision, and robustness, which restricts their applicability to erasing only a few hundred concepts.
We present Erasing Thousands of Concepts (ETC), a scalable framework capable of erasing thousands of concepts while preserving generation quality. ETC models low-rank concept distributions with a Student's t-distribution Mixture Model, performs pin-point target mapping via affine optimal transport, and trains a Mixture-of-Experts module, MoEraser, with a noise injection-restore strategy for robustness to module removal.
ETC turns concept erasure into distribution modeling, transport-based mapping, and scalable MoE training.
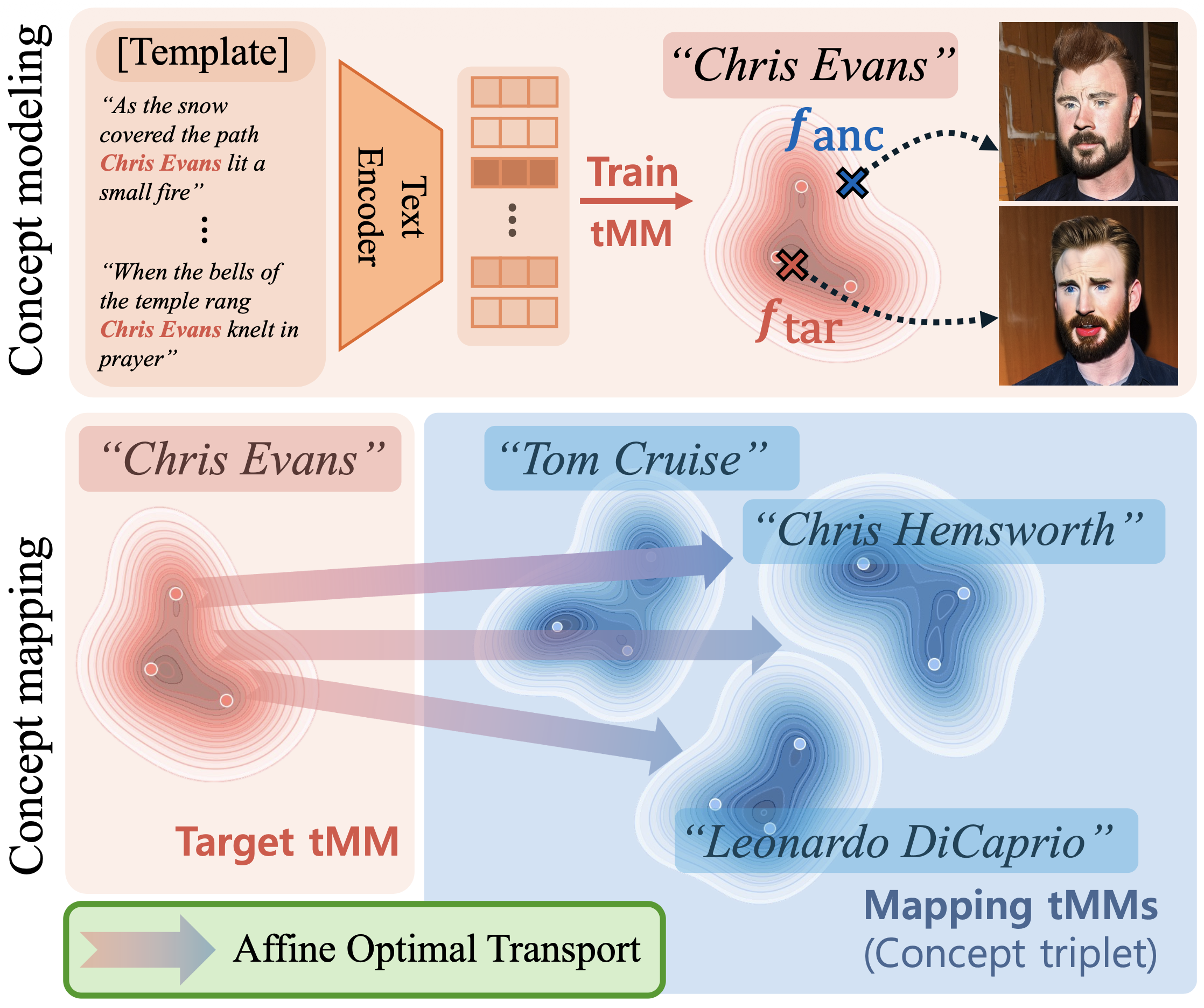
ETC captures contextual variation by fitting Student's t-distribution mixtures to low-rank text embedding distributions.
Target concept distributions are transported toward merged mapping concepts, producing anonymous replacement embeddings while avoiding curated anchor concepts.
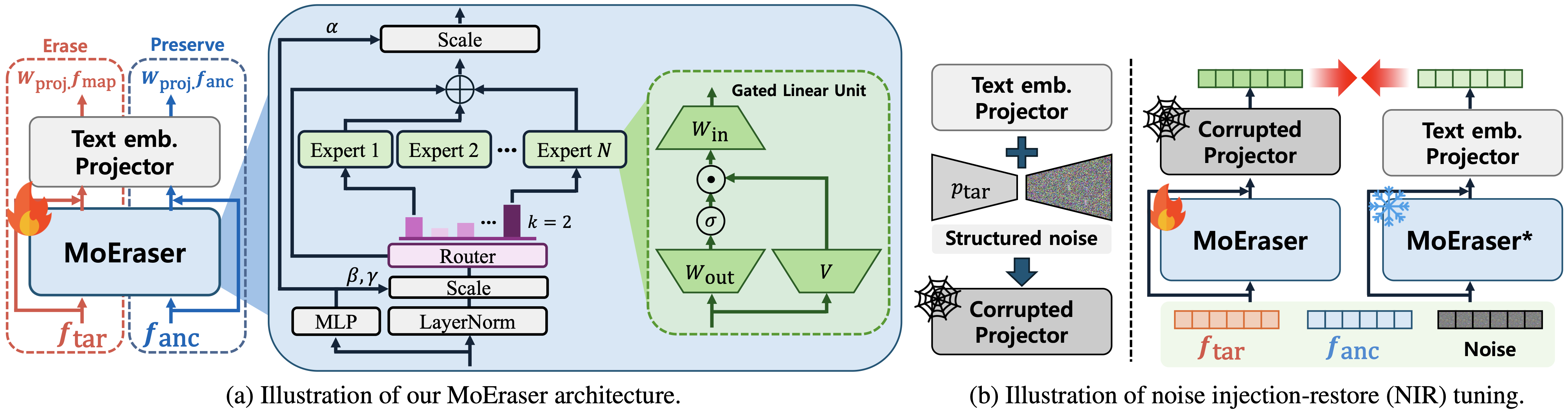
A Mixture-of-Experts erasing module transforms target embeddings, preserves anchors, and restores structured-noise-corrupted projectors to resist module removal.
ETC removes target concepts while keeping non-target concepts close to the original generation.

Key design choices behind ETC's scalability and robustness.

tMM attenuates concept presence more naturally in low-probability regions than GMM, matching the paper's boundary-based anchor construction.

AOT maps a target distribution toward a merged concept triplet, producing novel visual features instead of copying a single replacement identity.

NIR corrupts the text-embedding projector and trains MoEraser to restore usable embeddings, so removing the module degrades image generation.
@inproceedings{seo2026erasing,
title={Erasing Thousands of Concepts: Towards Scalable and Practical Concept Erasure for Text-to-Image Diffusion Models},
author={Seo, Hoigi and Lee, Byung Hyun and Cho, Jaehyun and Lim, Sungjin and Chun, Se Young},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026},
url={https://arxiv.org/abs/2604.16481}
}